Abstract
Machine unlearning for large language models aims to selectively remove memorized content — private data, copyrighted text, or hazardous knowledge — without costly full retraining. Most methods require a retain set of curated examples to prevent catastrophic utility loss, an extra data dependency that complicates deployment.
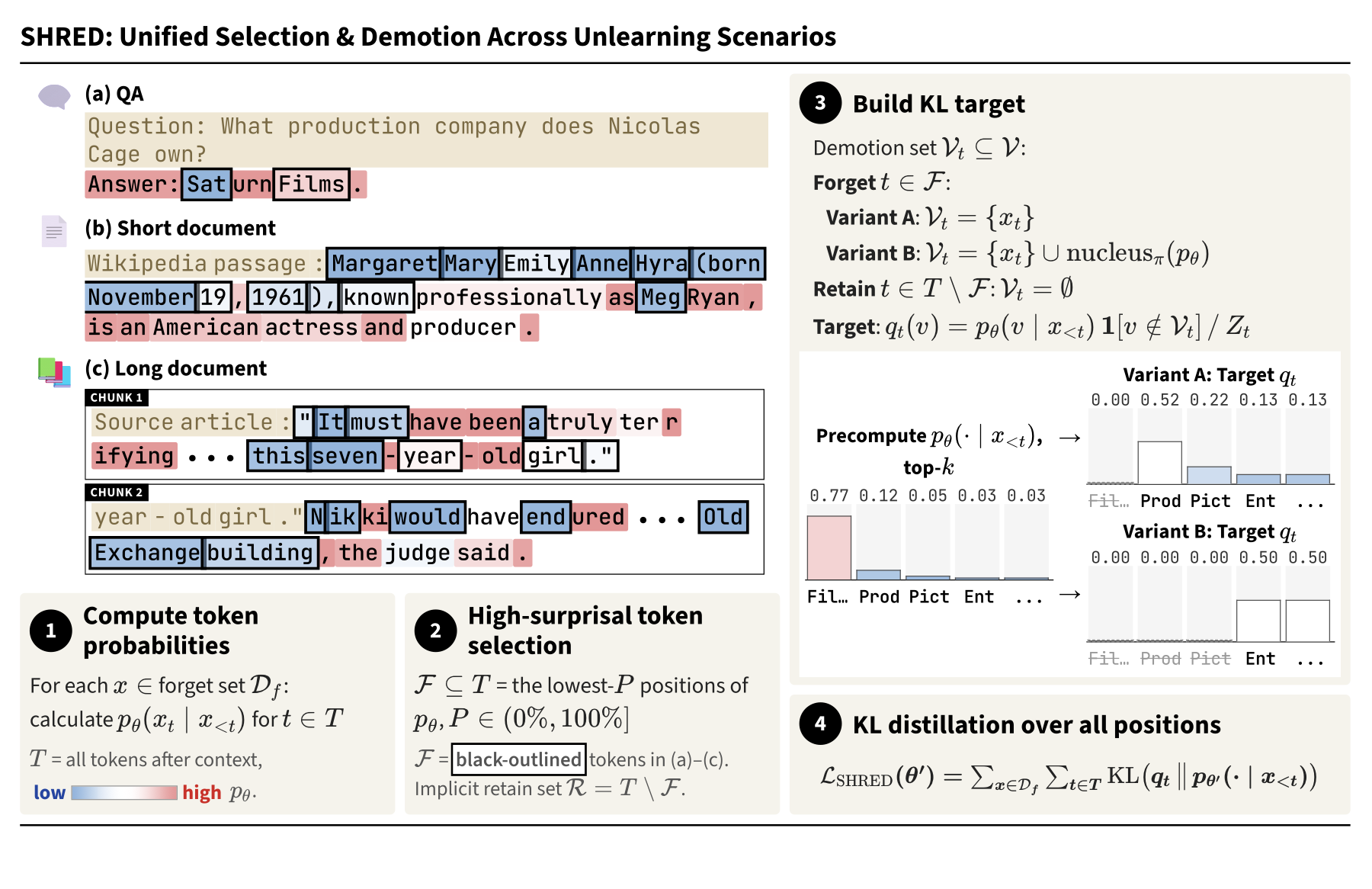
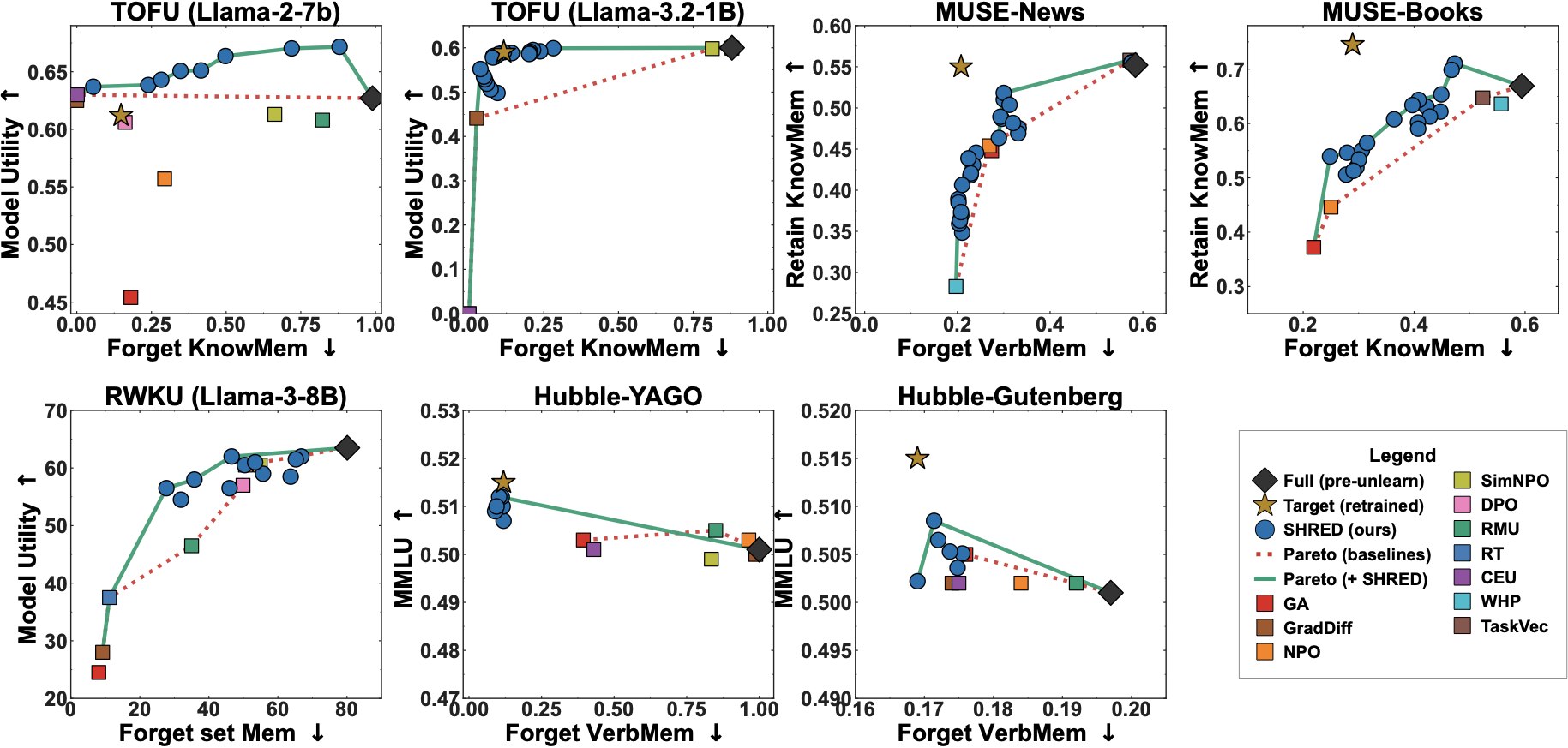
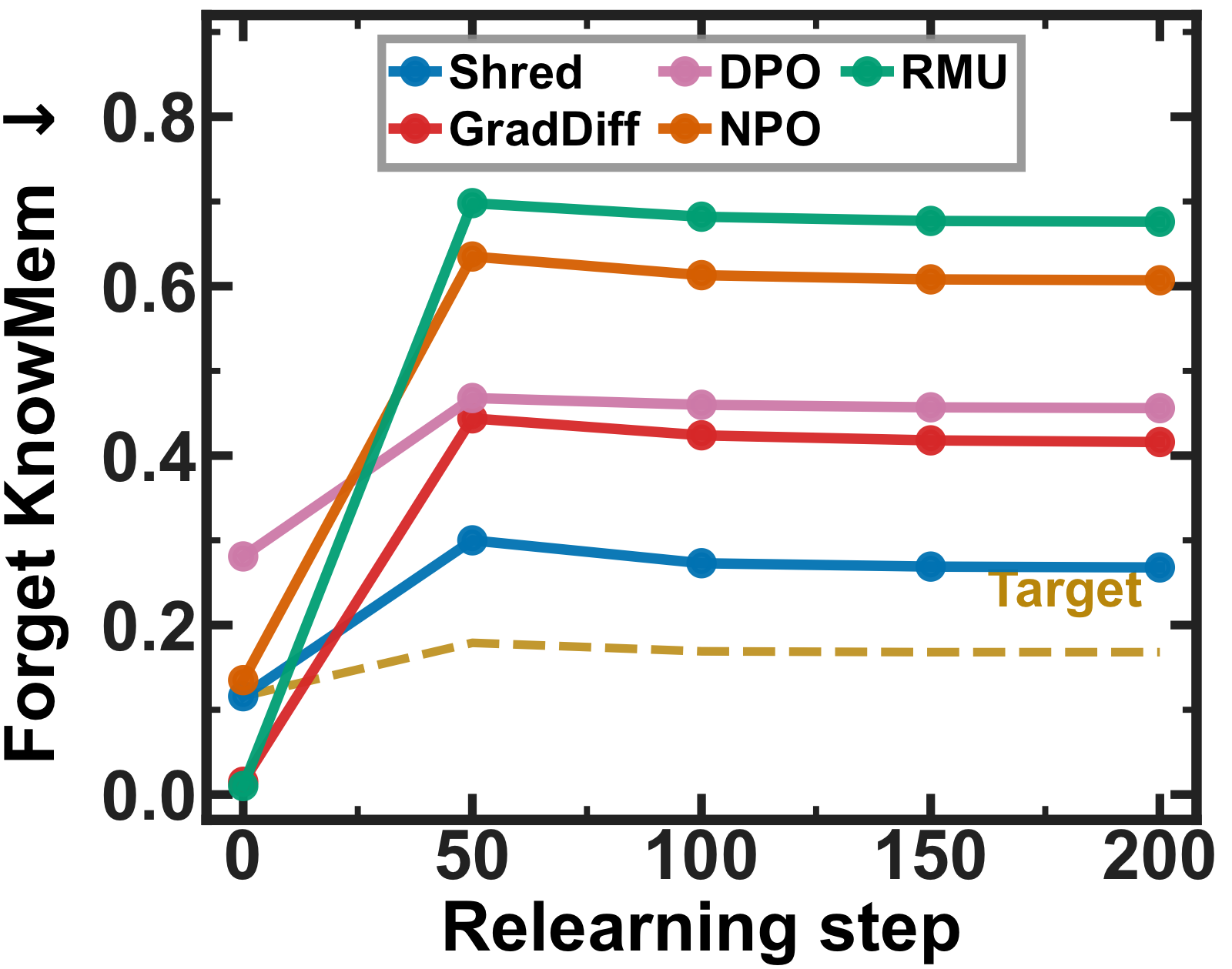
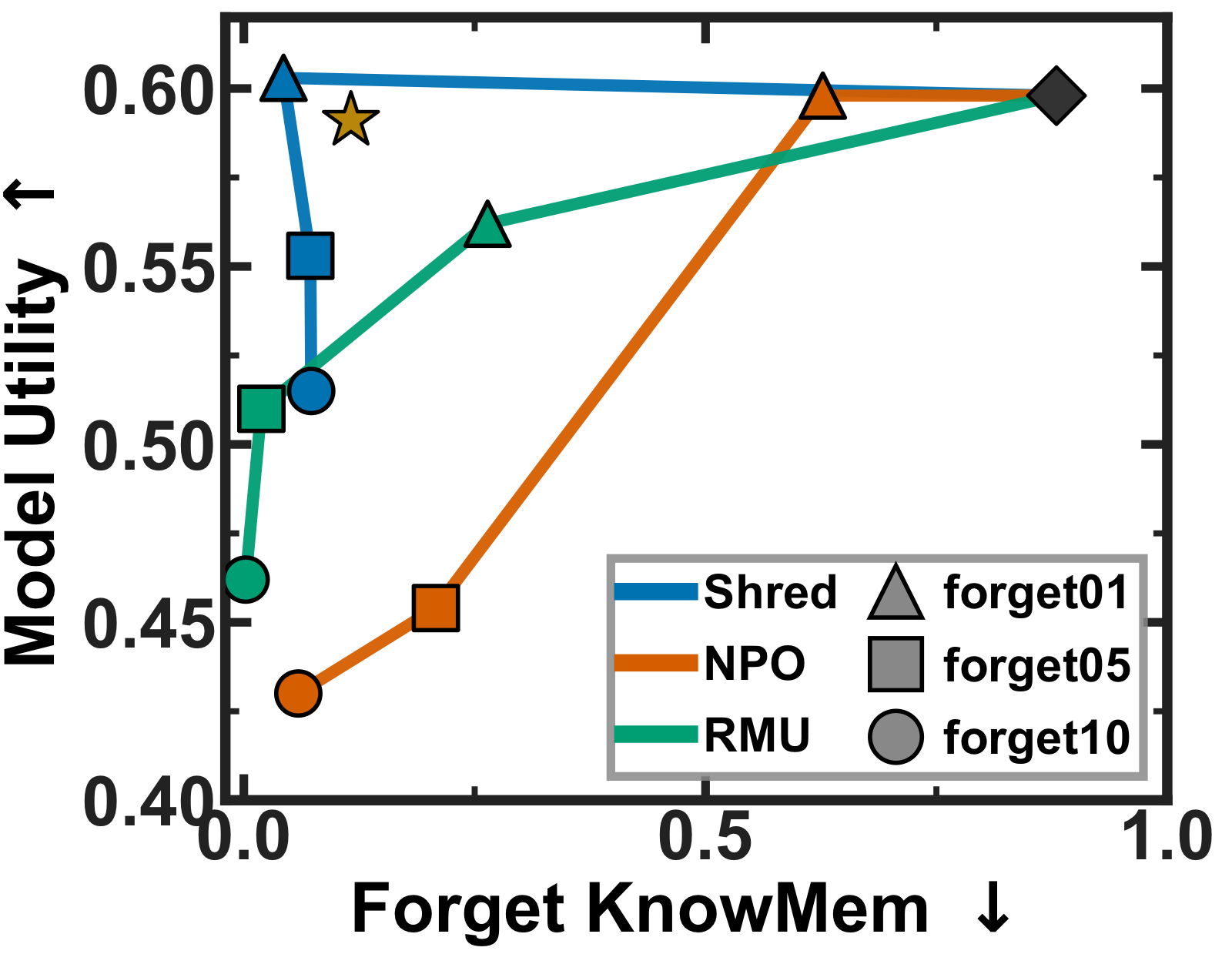
We propose SHRED, a retain-set-free unlearning method built on a key insight: not all tokens within a forget-set instance carry memorized information equally. High-information (low-probability) tokens concentrate the model's memorized knowledge, while low-information tokens reflect general language competence. SHRED (1) selects the bottom-P lowest-probability (highest-Shannon-information) positions as forget positions, and (2) trains the model with a single top-K KL self-distillation objective whose targets demote the memorized token's logit at forget positions while preserving the original distribution at benign anchor positions. This simultaneously drives forgetting and utility preservation — no retain set needed. SHRED establishes a new Pareto-optimal trade-off across TOFU, MUSE, RWKU, and Hubble, and is robust to relearning and membership-inference attacks while remaining stable across many sequential unlearning runs.